Estou estudando o curso Fundamentos de Engenharia de Dados da Data Science Academy. O segundo capítulo traz o Ciclo de vida da Engenharia de Dados. Neste artigo, vou resumir cada tópico do diagrama.
Fala, meus consagrados! Tudo beleza com vocês?
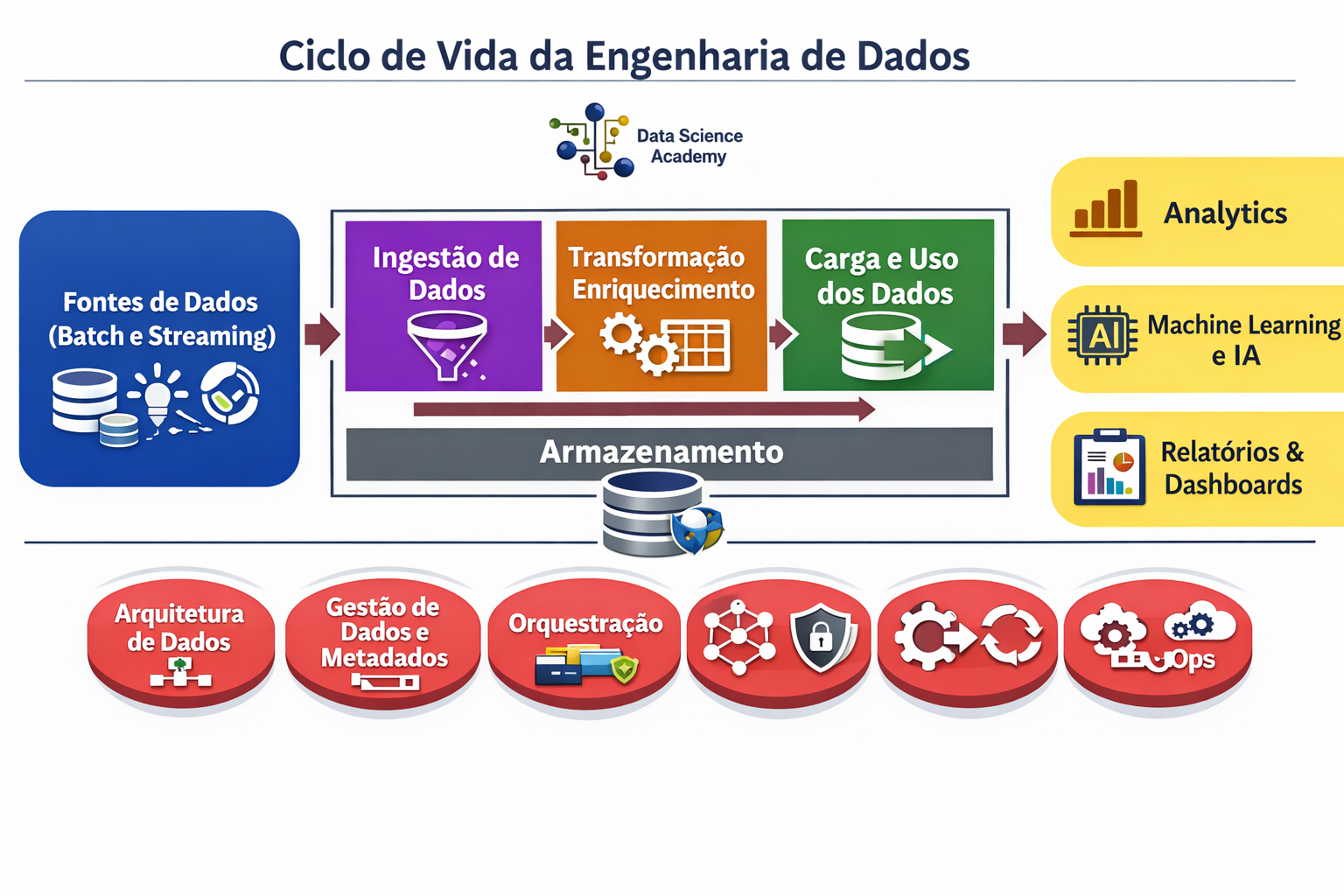
Explicando o diagrama
O diagrama apresenta o Ciclo de Vida da Engenharia de Dados como um fluxo ponta a ponta: os dados saem das fontes, passam por etapas técnicas de preparação e, ao final, são convertidos em valor para consumo analítico. No vídeo da Data Science Academy, esse diagrama é apresentado justamente como uma forma de consolidar a compreensão do que é Engenharia de Dados e de como essa área evoluiu para sustentar analytics, IA e dashboards.
O bloco “Fontes de Dados (Batch e Streaming)” representa a origem dos dados. Aqui estão sistemas transacionais, APIs, arquivos, sensores, logs, bancos relacionais, aplicações web e qualquer outra fonte produtora de eventos ou registros. A distinção entre batch e streaming é central: em batch, os dados chegam em lotes periódicos; em streaming, o fluxo é contínuo ou quase em tempo real. Esse ponto do diagrama mostra que a Engenharia de Dados começa muito antes da análise: ela começa na captura organizada e confiável da informação.
No centro do diagrama está o núcleo operacional do ciclo, composto por três etapas. A primeira é Ingestão de Dados, responsável por coletar os dados nas fontes e trazê-los para o ecossistema analítico. Nessa fase entram conectores, pipelines de extração, mensageria, captura de eventos e mecanismos de transferência. O foco é garantir que o dado chegue ao ambiente de dados com integridade, frequência adequada e rastreabilidade.
A segunda etapa é Transformação e Enriquecimento. Aqui o dado bruto é tratado para se tornar utilizável. Isso inclui limpeza, padronização, conversão de tipos, tratamento de nulos, deduplicação, junções entre fontes, regras de negócio, validações e agregações. O termo enriquecimento indica que o dado não é apenas corrigido: ele também recebe contexto adicional, como classificações, dimensões, chaves de integração e atributos derivados. Em termos práticos, é nessa fase que o dado deixa de ser apenas “registro coletado” e passa a ser “ativo informacional”.
A terceira etapa é Carga e Uso dos Dados. Depois de tratados, os dados são disponibilizados para consumo. Isso pode ocorrer em data warehouses, data lakes, lakehouses, marts analíticos ou camadas semânticas. O uso pode ser feito por analistas, cientistas de dados, times de BI, aplicações corporativas e modelos de aprendizado de máquina. O nome do bloco é importante porque não se trata apenas de “carga”: o objetivo final é colocar o dado em condição de uso efetivo.
A faixa horizontal de Armazenamento, posicionada abaixo das três etapas centrais, mostra que o armazenamento sustenta todo o ciclo. Ele não aparece como um ponto isolado, mas como uma base estrutural que atravessa a ingestão, a transformação e a disponibilização. Isso revela uma ideia importante: em Engenharia de Dados, armazenar não é somente guardar arquivos ou tabelas; é prover persistência, organização, escalabilidade, desempenho e governança para todo o ecossistema.
À direita, o diagrama mostra os principais produtos de valor gerados pelo ciclo. Analytics corresponde à exploração, análise e interpretação dos dados para apoiar decisões. Machine Learning e IA representa o uso dos dados preparados como insumo para modelos preditivos, classificadores, sistemas inteligentes e automações baseadas em dados. Relatórios e Dashboards correspondem à camada de visualização gerencial e operacional, muito comum em plataformas de BI. O encadeamento do diagrama deixa clara a lógica: a Engenharia de Dados não é um fim em si mesma; ela existe para viabilizar consumo analítico confiável.
Na parte inferior aparecem os elementos transversais que sustentam todas as fases do ciclo. Arquitetura de Dados define como as tecnologias, camadas e padrões se organizam. Gestão de Dados e Metadados trata de catálogo, linhagem, qualidade, significado e governança dos dados. Orquestração coordena a execução dos pipelines, dependências, horários e monitoramento das rotinas. Segurança cuida de controle de acesso, proteção, conformidade e prevenção de riscos. CI/CD aplica automação e versionamento aos artefatos de dados e pipelines. DataOps traz uma abordagem operacional contínua, com colaboração, observabilidade, testes e melhoria constante.
Em síntese, o diagrama comunica uma visão sistêmica da área: a Engenharia de Dados é a disciplina que coleta, movimenta, transforma, armazena, governa e entrega dados para que a organização consiga gerar análise, inteligência e decisão. No contexto do vídeo, o propósito do esquema é exatamente fechar essa visão integrada do processo, mostrando que a área não se resume a banco de dados ou ETL isolado, mas envolve um ciclo completo de geração de valor a partir dos dados.
Uma síntese do diagrama seria:
- Fontes de dados;
- Ingestão;
- Transformação/enriquecimento;
- Armazenamento;
- Disponibilização;
- Analytics, IA e dashboards.
Mais algumas informações
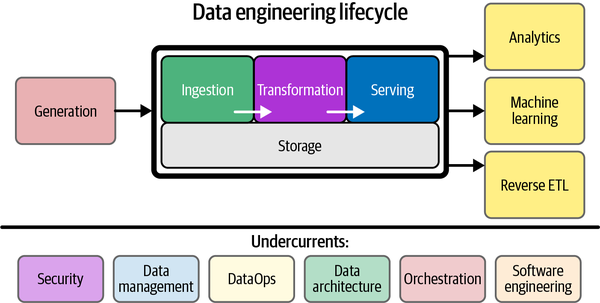
Esse diagrama foi criado de acordo com o livro Fundamentals of Data Engineering, da O’Reilly:
Também, há um artigo no blog do Data Science Academy sobre a carreira de Engenheiro de Dados.
Espero que gostem do conteúdo e desejo que se preparem conosco durante essa jornada na conquista de uma tão sonhada vaguinha em um concurso público.
É isso aí, galera.
[]’s e até a próxima.
——————————————
Professor Rogerão Araújo
www.instagram.com/profrogeraoaraujo
www.youtube.com/@profrogeraoaraujo
