Olá pessoal, tudo jóia ?!
Vamos de mais um artigo e agora com o objetivo de “esquentar os tamborins” para prova do TCU e nada melhor do que comentar questões de concursos anteriores.
Para este artigo escolhi questões que foram cobradas para o seguinte item do edital:
DESENVOLVIMENTO DE SISTEMAS: …..3 Modelagem dimensional e análise de requisitos para sistemas analíticos, ferramentas ETL e OLAP.
EDITAL Nº 8 – TCU-AUFC, DE 11 DE JUNHO DE 2015
Antes de comentarmos às questões, vamos fazer uma breve revisão sobre o assunto e depois partimos para o ataque na resolução.

Os tópicos elencados no edital e abordados nesta revisão estão inseridos, em alguns outros editais e em sua maioria, como sub-tópicos do assunto “Sistemas de apoio à decisão“. Vamos revisar alguns conceitos importantes, iniciando pelo Armazém de Dados (Datawarehouse). Veremos como alguns autores consagrados e usados pelas bancas de concursos falam sobre o tema:
“Datawarehouse é uma coleção de dados orientada por assuntos, integrada, não volátil e variável em relação ao tempo, que tem por objetivo dar suporte aos processos de tomada de decisão”.
“Datawarehouse é todo processo que provê informação para o suporte à tomada de decisão”.
Inmon e Kimball
“Datawarehouse é um banco de dados que armazena dados correntes e históricos de potencial interesse para os tomadores de decisão de toda a empresa. Os dados originam-se de muitos sistemas operacionais centrais, como sistemas de vendas, contas de clientes e manufatura, podendo incluir ainda dados advindos de transações em sites. O datawarehouse consolida e padroniza as informações oriundas de diferentes bancos de dados operacionais, de modo que elas possam ser usadas por toda empresa para análise gerencial e tomada de decisões”.
Laudon & Laudon
Vamos conhecer as principais arquiteturas usadas para implementar um DW:
Datawarehouse Empresarial (Enterprise Datawarehouse – EDW):
Suporta toda ou maior parte dos requisitos ou necessidades. Ele possui grande grau de acesso e a utilização das informações é para todos os departamentos de uma empresa.
Nas questões de provas o termo EDW é pouco usado, o mais usual é o DW.
Data Mart:
É um DW projetado para uma unidade estratégica de negócios ou um departamento, mas cuja fonte não é um EDW (ou DW). Eles são fáceis de construir, porém, envolvem altos custos, redundância de dados e não permitem uma visão global da empresa.
A decisão de qual arquitetura implementar pode causar impactos quanto ao sucesso do projeto de um DW. Diversos fatores influenciam a escolha da arquitetura e implementação, entre elas o tempo para execução do projeto, a necessidade urgente de um DW, o retorno do investimento a ser realizado, a velocidade dos benefícios da utilização das informações , a limitação de recursos, a satisfação do usuário executivo, a compatibilidade com sistemas existente e os recursos necessários à implementação de uma arquitetura.
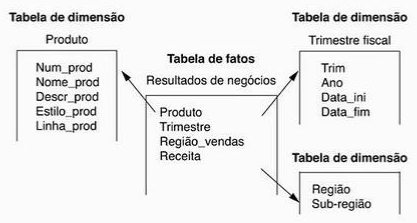
O modelo de armazenamento multidimensional evolve dois tipos de tabelas:
1. Tabelas de Fatos: É a tabela central do projeto dimensional, armazenando medições numéricas de negócio. Possui chaves de múltiplas partes, sendo que cada chave é uma chave externa para uma tabela de dimensão. Cada medição recebe como o valor o resultado da interseção com as dimensões. Consultas realizadas nas tabelas fato podem retornar milhares de registros.
Quanto as suas medições ou dados de medidas, podem ser de vários tipos:
- a) Aditivas: É o resultado da soma dos valores gerados pela seleção dos membros das dimensões, sendo o resultado desta soma mostrado como métrica da tabela fato;
- b) Semi-aditivas: É a soma resultante de partes das suas dimensões;
- c) Não aditivas: São medidas que não podem ser somadas em nenhuma dimensão.
2. Tabelas de Dimensão: É representação do contexto relevante para o negócio da organização ou departamento. Um exemplo seria uma tabela fato “Compras” com tabelas de dimensão “Fornecedores”, “Material”, “Local”. As tabelas de dimensão podem possuir membros e serem organizadas por hierarquia.
- a) Membros: Um exemplo de membros na dimensão “Fornecedor” seria: “ nome, CNPJ, telefone”;
- b) Hierarquia: Um exemplo do uso de hierarquia na dimensão “Material” seria: “Grupo -> Classe -> Item”.
“Dois esquemas multidimensionais comuns são o esquema estrela (star-schema) e o esquema floco de neve (snowflake). O esquema estrela consiste em uma tabela de fatos com uma única tabela para cada dimensão. O esquema floco de neve é uma variação do esquema estrela, em que as tabelas dimensões de um esquema estrela são organizadas em uma hierarquia ao normalizá-las.”
Navathe
Resumindo, o esquema floco de neve é um esquema estrela normalizado. Tal normalização, no caso do esquema floco de neve, vai até a 3FN podendo inclusive surgir relacionamentos do tipo N:N (muitos-para-muitos).
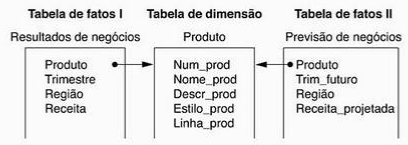
Uma constelação de fatos é um conjunto de tabelas fatos que compartilham algumas tabelas de dimensão. O problema é que as consultas realizadas nestas constelações tornam-se limitadas.
Vamos ver alguns exemplos visuais:
Esquema Estrela

Esquema Floco de Neve
Constelação de Fatos
“OLAP (processamento analítico on-line) é um termo usado para descrever a análise de dados complexos do Datawarehouse. Nas mãos de trabalhadores habilidosos no conhecimento, as ferramentas OLAP utilizam capacidades de comparação distribuída para análises que exigem mais armazenamento e poder de processamento do que pode estar localizado economicamente e eficientemente em um desktop individual”.
“Os bancos de dados tradicionais têm suporte para o processamento de transação on-line(OLTP), que inclui inserções, atualizações e exclusões, enquanto também têm suporte para requisitos de consulta de informação. Os bancos de dados relacionais tradicionais são otimizados para processar consultas que podem tocar em uma pequena parte do banco de dados e transações que lidam com inserções ou atualizações no processo de algumas tuplas por relação. Assim, eles não podem ser otimizados para OLAP, DSS (SAD) ou mineração de dados (data mining)”.
Navathe
Bizu do Luis para diferenciar OLAP x OLTP
| CARACTERÍSTICA | OLTP | OLAP |
| Operação Típica | Atualização | Análise |
| Telas | Imutável | Definida pelo usuário |
| Nível de Dados | Atomizado | Altamente sumarizado |
| Idade dos Dados | Presente | Histórico, atual, projetado |
| Recuperação | Poucos Registros | Muitos Registros |
| Orientação | Registro | Arrays |
| Modelagem | Processo | Assunto |
Tentem decorar a tabela acima, pois ela pode salvar algumas questões.
Para finalizar o resumo sobre OLAP, vamos rever os 12 Regras para Aplicações OLAP de Edgar Frank Codd:
- Conceito de visão multidimensional;
- Transparência;
- Acessibilidade;
- Performance consistente de relatório;
- Arquitetura cliente/servidor;
- Dimensionamento genérico;
- Tratamento dinâmico de matrizes esparsas;
- Suporte a multiusuários;
- Operações de cruzamento dimensional irrestritas;
- Manipulação de dados intuitiva;
- Relatórios flexíveis;
- Níveis de dimensões e agregações ilimitados.
As regras acima descritas fazem parte da análise de qualquer ferramenta OLAP, ou seja, a ferramenta deve dispor destas características para que de fato seja considerada uma ferrramenta OLAP. Quase todas as descrições são auto-explicativas, porém o item 7 merece melhor detalhamento:
A esparsidade de uma matriz é a relação entre o número de elementos nulos de uma matriz e o número total de elementos da matriz – grau de esparsidade é a porcentagem de elementos nulos da matriz. São matrizes em que nem todos os elementos estão realmente presentes ou são necessários, portanto, a maioria das posições são preenchidas por zeros. Pode-se economizar um espaço significativo de memória se apenas os termos diferentes de zero forem armazenados e manuseados tornando maior a eficiência computacional.
Vimos durante nosso resumo que um DW utiliza dados vindos de diversas fontes, então imagino que vocês devam ter pensado: “Como isso é possível ?” , “…mas, cada lugar define a mesma coisa de forma diferente, como se faz para unificar tudo ?”.
Para responder estas dúvidas, vamos conhecer o processo ETL.
O ETL (Extract, Transform and Load), ou seja, extração, transformação e carga, trata-se de um processo primordial na inserção dos dados em um DW. Imagine vários bancos de dados de diferentes sistemas, onde muitas das vezes alguns dados trazem a mesmo conteúdo de forma diferente, porém todos os dados irão para um mesmo lugar: o DW.
Pra garantir que os dados mantenham um mesmo padrão, se faz necessário realizar um trabalho prévio de transformação destes dados, para que eles sigam uma mesma linha e em seguida sejam carregados no DW. Resumidamente é isto que o processo ETL faz.

A primeira parte do processo de ETL é a extração de dados dos sistemas de origem. A maioria dos projetos de data warehouse consolidam dados extraídos de diferentes sistemas de origem. Cada sistema pode também utilizar um formato ou organização de dados diferente, relacionais ou não relacionais, convertendo para um determinado formato para a entrada no processamento da transformação.
A etapa de transformação aplica uma série de regras ou funções aos dados extraídos para derivar os dados a serem carregados. Algumas fontes de dados necessitarão de muito pouca manipulação de dados.
A etapa de carregamento consiste na colocação dos dados no Data Warehouse (DW). Dependendo das necessidades da organização, este processo varia amplamente. Alguns DWs podem substituir as informações existentes semanalmente, com dados cumulativos e atualizados, ao passo que outro DW pode adicionar dados a cada hora. A temporização e o alcance de reposição ou acréscimo constituem opções de projeto estratégicas que dependem do tempo disponível e das necessidades de negócios.
Afim de permitir o desenvolvimento de vários métodos para melhorar a performance geral dos processos de ETL no tratamento de grandes volumes de dados, é realizado o uso do paralelismo, onde os três mais conhecidos são: Dados, pipeline e componentes.
- Paralelismo de Dados: dados são particionados para que haja acesso paralelo;
- Paralelismo de Pipeline: permite a execução simultânea de diversos componentes no mesmo fluxo de dados;
- Paralelismo de Componentes: a execução simultânea de múltiplos processos em diferentes fluxos de dados no mesmo job. A classificação de um arquivo de entrada concomitantemente com a de duplicação de outro arquivo seria um exemplo de um paralelismo de componentes.
Na fase de transformação é comum os dados extraídos ficarem armazenados em uma base dados transitória, ou seja, uma base de dados que antecede a carga para o DW, chamada de Staging Area. Existem, segundo muitos autores, duas formas de staging area, vamos conhecê-las:
1. ODS (Operational Data Storage): armazenamento intermediário de dados, com o objetivo de facilitar a integração dos dados dos sistemas transacionais antes da carga no DW. As informações são voláteis e passíveis de descarte após a carga no DW.
2. DDS (Dynamic Data Storage): diferentemente do ODS, os dados não são voláteis e permanecem incrementais ao longo do tempo. Caso a granularidade do DDS seja compatível com o DW, os dois acabam se confundindo e há a preocupação de duplicidade de dados.
Vejamos agora algumas operações que podem ser realizadas em um modelo dimensional, porém antes, vamos conhecer sobre os conceitos de Granularidade e Cubo:
Granularidade: Uma das etapas da modelagem dimensional é a definição da granularidade das informações em cada dimensão, ou seja, qual é o nível de detalhe desejado. Quanto mais detalhado for o dado, mais baixa será sua granularidade, por sua vez quanto menos detalhado for o dado, mas alta será sua granularidade. A vantagem do dado mais detalhado é que o usuário poderá avaliar a informação em qualquer nível de agregação, porem isso vai aumentar o volume de dados, prejudicando o desempenho do sistema. Já no nível mais alto, ou seja, com menos detalhe, existe a desvantagem de o usuário ficar limitado a consultas pouco detalhadas, porém o desempenho é melhor por armazenar poucos dados.
Cubo: É a forma como os dados se apresentam num modelo dimensional, onde a representação dos dados é estruturada no formato de cubo, dando a ideia de múltiplas dimensões.
As funcionalidades que vamos ver agora são as seguintes:
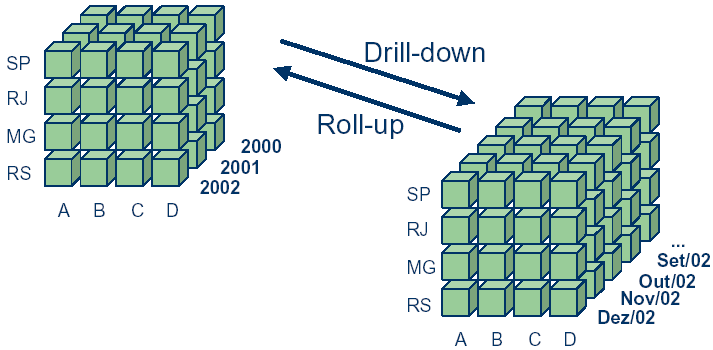
Drill Down: Realiza o detalhamento os dados. O usuário desagrupa os dados aumentando o nível de detalhe da informação. Roll Up (Drill Up): Os dados são resumidos com generalização cada vez maior, sendo o contrario do drill down, reduzindo o nível de detalhe da informação.
Slice and Dice: A operação Slice é aplicada quando um membro de uma dimensão é selecionado, formando uma espécie de fatia (slice) ou subcubo do cubo original. Já o Dice seleciona vários membros de dimensões diferentes, formando um subcubo.


Pivot: Realiza rotação dos dados, mudando o ângulo de visão, permitindo a troca linhas por colunas em uma tabela.

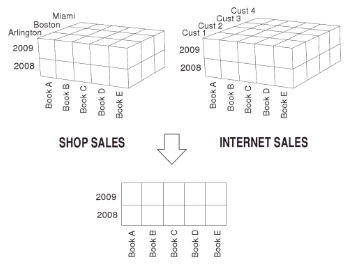
Drill Across: Constrói consultas envolvendo mais de uma tabela fato, contanto que os dois cubos possuam, pelo menos, uma dimensão em comum, ou seja, uma operação sobre dois cubos. É possível encontrar outras interpretações, por sinal muito contestadas, como por exemplo considerar que ao usar duas tabelas fatos, o usuário resolva pular um dado intermediário dentro de uma mesma dimensão, ou seja, o usuário poderia estar usando o drill across quando passar de ano direto para mês.
Drill Through: Ocorre quando o usuário passa de uma informação de uma dimensão para outra, detalhando-a até seu nível operacional. Um exemplo seria o usuário está avaliando dados numa dimensão de tempo e logo passar o mesmo dado para outra dimensão a qual não possui hierarquia com a dimensão tempo, por exemplo, uma dimensão de unidade federativa ou região.
E aí pessoal, vamos para o que interessa agora?! “Simbora” resolver questões !!
Questões de concursos
CESPE 2015 TCU – Auditor Federal de Controle Externo – Tecnologia da Informação
Julgue o item subsequente, a respeito de modelagem dimensional e análise de requisitos para sistemas analíticos.
Na análise dos dados de um sistema com o apoio de uma ferramenta OLAP, quando uma informação passa de uma dimensão para outra, inexistindo hierarquia entre elas, ocorre uma operação drill through.
Comentários:
Vimos em nosso resumo às diferentes operações em dados distribuídos em um modelo multidimensional, dentre eles o driil throgh, que tem como característica o fato de poder comparar um determinado de dado de uma dimensão para outra que não faça parte de sua própria hierarquia.
Sendo assim, certa a questão.
Gabarito: CERTO.
CESPE 2015 TCU – Auditor Federal de Controle Externo – Tecnologia da Informação
Julgue o item subsequente, a respeito de modelagem dimensional e análise de requisitos para sistemas analíticos.
Entre os requisitos de análise de uma aplicação OLAP inclui-se a capacidade de tratar dinamicamente a esparsidade das informações para restringir o cruzamento dimensional de matrizes com células de valor zero.
Comentários:
Essa uma daquelas questões onde o candidato, por empolgação, erra por não ler com atenção. De fato, o controle dinâmico da esparsidade ou matriz esparsas faz parte de um dos requisitos para aplicação OLAP, porém, não é para restringir o cruzamento dimensional de matrizes com células de valor zero, na verdade, as colunas não preenchidas são suprimidas no armazenamento. Errada a questão.
Gabarito: ERRADO.
CESPE 2015 TCU – Auditor Federal de Controle Externo – Tecnologia da Informação
Julgue o item subsequente, a respeito de modelagem dimensional e análise de requisitos para sistemas analíticos.
O paralelismo, característica desejável de uma ferramenta de ETL, oferece suporte às operações de vários segmentos e a execução de código executável de forma paralela.
Comentários:
Em nosso resumo vimos que o uso do paralelismo contribui e muito na performance do processo ETL. Os motivos para o seu uso podem ser diversos, a começar pelo volume e variedade de dados na origem, o que muitas vezes requer a implementação de diferentes jobs a serem executados, uso de diferentes ferramentas para tratamento de dados e que por sua vez são ferramentas que passam por parametrização prévia. Diante disto, podemos com segurança afirmar que a questão está certa.
Gabarito: CERTO.
CESPE 2015 TCU – Auditor Federal de Controle Externo – Tecnologia da Informação
Julgue o item subsequente, a respeito de modelagem dimensional e análise de requisitos para sistemas analíticos.
Em uma modelagem dimensional que utilize o esquema estrela, a chave primária de uma tabela de fatos será a chave estrangeira na tabela de dimensões.
Comentários:
Em nosso resumo vimos que em um esquema estrela ocorre justamente o contrário, ou seja, a tabela central do projeto dimensional (tabela fato) armazena medições numéricas de negócio. Possui chaves de múltiplas partes, sendo que cada chave é uma chave externa para uma tabela de dimensão, ou seja, a tabela fato armazena as chaves estrangeiras, as quais são primárias nas tabelas de dimensão. Errada a questão.
Gabarito: ERRADO.
Bom, por hoje é só. No próximo artigo trarei as questões de Data Mining do TCU/2015.
Um forte abraço e bons estudos.
Luis Octavio Lima


Pingback: QUESTÕES COMENTADAS DO TCU/2015: DATA MINING | Professor Rogerão Araújo