Olá pessoal, como estamos?!
Vamos de mais um artigo de resolução de questões do concurso do TCU/2015. Neste artigo irei abordar às questões sobre Data Mining. Observando o nível das questões sobre assunto neste concurso, é possível perceber que o nível foi de mediano para fácil, nenhum “bicho de sete cabeças”.

Neste edital, o assunto Data Mining foi cobrado da seguinte forma:
ANÁLISE DE INFORMAÇÕES: …….. 4 Noções de mineração de dados: conceituação e Características. Modelo de referência CRISP-DM. Técnicas para pré-processamento de dados. Técnicas e tarefas de mineração de dados. Classificação. Regras de associação.
EDITAL Nº 8 – TCU-AUFC, DE 11 DE JUNHO DE 2015
Análise de agrupamentos (clusterização). Detecção de anomalias. Modelagem preditiva. Aprendizado de máquina. Mineração de texto.
Antes da leitura deste artigo, recomendo a leitura do artigo anterior (QUESTÕES COMENTADAS DO TCU/2015: MODELAGEM DIMENSIONAL, OLAP E ETL) onde foram tratados muitos conceitos importantes e que se acumulam com o que iremos explorar neste artigo.
A definição sobre Data Mining é bem difundida na literatura e para não “chover no molhado”, trago abaixo algumas citações dos autores “mais queridos” das bancas, principalmente a banca CESPE, vejamos:
“A mineração de dados pode ser usada junto com um data warehouse para ajudar com certos tipos de decisões. A mineração de dados pode ser aplicada a banco de dados operacionais com transações individuais. Para tornar a mineração de dados mais eficiente, o data warehouse deve ter uma coleção de dados agregada ou resumida. ”
“Para ser útil na prática, a mineração de dados precisa ser executada de modo eficiente em grandes arquivos e bancos de dados. Embora alguns recursos de mineração de dados estejam sendo fornecidos em SGBDRs , ela não é bem integrada aos sistemas de gerenciamento de banco de dados”.
Navathe
“O data mining fornece percepções dos dados corporativos que não podem ser obtidas com o OLAP, descobrindo padrões e relacionamentos ocultos em grandes bancos de dados e inferindo regras a partir deles para prever comportamentos futuros. Estes modelos e regras podem então ser utilizados para guiar o processo de decisão e prever o efeito dessas decisões”.
Laudon & Laudon
A descoberta de conhecimento nos bancos de dados, abreviada como KDD (Knowledge Discovery in Databases), normalmente abrange mais do que a mineração de dados. O processo de descoberta de conhecimento compreende seis fases: seleção de dados, limpeza de dados, enriquecimento, transformação ou codificação de dados, mineração de dados e o relatório e exibição da informação descoberta .
Por exemplo, durante a seleção de dados, dados sobre itens específicos ou categorias de itens, ou de lojas em uma região ou área específica do país, podem ser selecionados. O processo de limpeza de dados, então, pode corrigir códigos postais inválidos ou eliminar registros com prefixos de telefone incorretos. O enriquecimento normalmente melhora os dados com fontes de informações adicionais. A transformação de dados e a codificação podem ser feitas para reduzir a quantidade de dados, por exemplo, através de agrupamentos. É somente depois do pré-processamento que as técnicas de mineração de dados são usadas para extrair diferentes regras e padrões.
Podemos então perceber que o processo KDD é muito mais amplo do que a mineração de dados em si. A mineração de dados e suas técnicas fazem parte do processo, ma não é o processo em si (atenção com essa “casca de banana”, o CESPE ama 😉 ).

Etapas do KDD
Vamos detalhar cada fase do KDD mais adiante neste artigo. Antes disso, vamos conhecer quais são os principais objetivos da mineração de dados.
Objetivos da mineração de dados (Data Mining) e da descoberta do conhecimento
a) Previsão: alguns exemplos de mineração de dados previsível incluem a análise de transações de compra para prever o que os consumidores comprarão sobe certos descontos, quanto volume de vendas uma loja gerará em determinado período e se a exclusão de uma linha de produto gerará mais lucro.
b) Identificação: os padrões de dados pode ser usados para identificar a existência de um item, evento ou atividade. Por exemplo, intrusos tentando quebrar um sistema podem ser identificados pelos programas executados.
c) Classificação: a mineração de dados pode particionar os dados de modo que diferentes classes ou categorias que possam ser identificadas com base em combinações parâmetros. Por exemplo, os clientes em um supermercado podem ser categorizados em compradores que buscam descontos, compradores com pressa, compradores regulares leais, compradores ligados a marcas conhecidas e compradores eventuais. Alguns outros autores chamam de isto de análise de clusters.
d) Otimização: outro objetivo da mineração de dados pode ser otimizar o uso de recursos limitados, como tempo, espaço, dinheiro ou materiais e examinar variáveis de saída como vendas ou lucros.
Tipos de conhecimento descobertos durante a mineração de dados
O conhecimento normalmente é classificado como indutivo versus dedutivo. O conhecimento dedutivo deduz novas informações com base na aplicação de regras lógicas previamente especificadas de dedução sobre o dado indicado. A mineração de dados foca no conhecimento indutivo, que descobre novas regras e padrões com base nos dados fornecidos.
O conhecimento pode ser representado de várias maneiras: em um sentido desestruturado, ele pode ser representado por regras ou pela lógica proposicional. Em uma forma estruturada, ele pode ser representado em árvores de decisão, redes semânticas, redes neurais ou hierarquia de classes.
As tarefas da mineração de dados podem pertencer a duas diferentes categorias: descritiva e a preditiva.
A categoria descritiva busca apresentar os conjuntos de dados de maneira concisa com foco informativo, já a categoria preditiva busca construir um modelo onde ao se usar dados ainda desconhecido seja possível apontar tendências e padrões.
Vejamos abaixo como às tarefas são agrupadas em cada uma destas categorias.
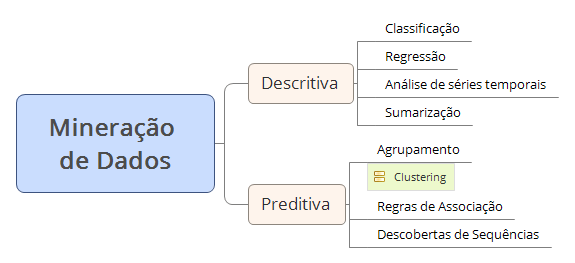
Vamos conhecer um pouco sobre cada uma destas tarefas:
Classificação
É o processo de encontrar um conjunto de modelos (funções) que descrevem e distinguem classes ou conceitos, com o propósito de utilizar o modelo para predizer a classe de objetos que ainda não foram classificados. O modelo construído baseia-se na análise prévia de um conjunto de dados de amostragem ou dados de treinamento, contendo objetos corretamente classificados (rotulados). Nesta tarefa, geralmente são usadas técnicas como Árvores de Decisão e Redes Neurais, já nos métodos de classificação usa-se técnicas de estatísticas e de aprendizado de máquina.
Regressão
Enquanto que a classificação tenta prever à qual classe determinado objeto pertence, a regressão busca prever um valor número contínuo, ou seja, enquanto a primeira foca em por exemplo dizer se um objeto deve receber um rótudo “verdadeiro/falso”, o segundo foca em , por exemplo, saber qual “o valor de vendas para o próximo mês”. Para esta tarefa são usados algorítimos de Regressão Linear Simples e Múltipla, Regressão Não Linear Simples e Múltipla.
Análise de Séries Temporais
É uma tarefa aplicada em banco de dados que contenham valores em sequencia armazenados em função do tempo. Esses valores devem ser obtidos no mesmo intervalo de tempo para possibilitar a análise, como a cada dia, hora ou minuto.
Sumarização
Consiste em mapear os dados em subconjuntos e em vários níveis. Diversas operações são utilizadas, como média, mediana, moda, desvio padrão, bem como derivação de regras de sumarização.
Agrupamento (clustering)
Comparando com a tarefa de Classificação, consiste no fato de agrupar dados onde não há uma classificação (rótulos) pré-existente. Para esta tarefa são usados algorítimos que conseguem perceber o grau de similaridade nos dados afim de formar agrupamentos e assim gerar novas classes.
Regras de Associação
É um padrão na forma a -> b , onde geralmente representa um padrão de comportamento onde na presença de um elemento “a” haverá um elemento “b” associado. É muito comum e fácil de entender a sua aplicação em supermercados, onde um cliente ao escolher um produto associa logo outro produto junto.
Descoberta de Sequências
É um padrão sequencial observado na linha do tempo, onde existe a tendência de acontecimentos ocorrerem relacionados, porem em momentos seguintes. Um exemplo é uma pessoa que compra um carro, com o passar de certo tempo ela comprará pneus.
Análise de Outliers
Trata-se de tarefa assessória que pode ser utilizada em conjunto com uma ou mais tarefas na Mineração de Dados. Um banco de dados pode conter dados que não apresentam o comportamento geral da maioria. Estes dados são denominados outliers (exceções). Muitos métodos de mineração descartam estes outliers como sendo ruído indesejado. Entretanto, em algumas aplicações, tais como detecção de fraudes, estes eventos raros podem ser mais interessantes do que eventos que ocorrem regularmente.
Todas estas tarefas e técnicas tem como principal finalidade a busca do conhecimento, para que seja possível tomar uma decisão mais acertada dentro de um determinado objetivo. Para isso, existe um processo chamado de Descoberta do Conhecimento em Banco de Dados (Knowledge Discovery in Databases – KDD), constituído pelas seguintes etapas:
- Seleção: etapa onde são selecionados os atributos que interessam ao usuário. Por exemplo, o usuário pode decidir que informações como endereço e telefone não são de relevantes para decidir se um cliente é um bom comprador ou não.
- Pré-processamento e Limpeza: é uma parte crucial no processo de KDD, pois a qualidade dos dados vai determinar a eficiência dos algoritmos de mineração. Nesta etapa deverão ser realizadas tarefas que eliminem dados redundantes e inconsistentes, recuperem dados incompletos e avaliem possíveis dados discrepantes ao conjunto, chamados de outliers
- Transformação dos Dados: é a fase do KDD que antecede a fase de Data Mining. Após serem selecionados, limpos e pré-processados, os dados necessitam ser armazenados e formatados adequadamente para que os algoritmos possam ser aplicados. Em grandes corporações é comum encontrar computadores rodando diferentes sistemas operacionais e diferentes Sistemas Gerenciadores de Bancos de Dados (SGDB). Estes dados que estão dispersos devem ser agrupados em um repositório único.
- Mineração: etapa essencial do processo consistindo na aplicação de técnicas inteligentes a fim de se extrair os padrões de interesse.
- Interpretação e Avaliação: A Mineração de Dados trás consigo uma série de ideias e técnicas para uma vasta variedade de campos. Estatísticos, pesquisadores de Inteligência Artificial (IA) e administradores de bancos de dados usam técnicas diferentes para interpretar e avaliar os resultados obtidos com a mineração para, no final, chegar a um mesmo fim: a informação.
Agora, chegou a hora, vamos para às questões! 🙂
CESPE 2015 TCU – Auditor Federal de Controle Externo – Tecnologia da Informação
No que concerne a data mining (mineração de dados) e big data, julgue o seguinte item.
No ambiente organizacional, devido à grande quantidade de dados, não é recomendado o emprego de data mining para atividades ligadas a marketing.
Comentários:
Questão absurdamente errada. Vimos durante o resumo que o uso de Data Mining no processo de KDD não distingue área de atuação, muito menos a área de marketing de uma organização. Já a grande quantidade de dados é justamente a premissa para o uso da mineração de dados, ou seja, as atividades de mineração se justificam por conta da grande quantidade e variedade de dados existentes.
Gabarito: ERRADO.
CESPE 2015 TCU – Auditor Federal de Controle Externo – Tecnologia da Informação
No que concerne a data mining (mineração de dados) e big data, julgue o seguinte item.
A finalidade do uso do data mining em uma organização é subsidiar a produção de afirmações conclusivas acerca do padrão de comportamento exibido por agentes de interesse dessa organização.
Comentários:
Essa questão foi polêmica, gerou diversos recursos, mas o resultado não mudou. A polêmica foi sobre o termo “afirmações conclusivas“, isso porque durante todo o processo de construção do conhecimento através do KDD e do uso da mineração de dados, o que temos é uma grande probabilidade de algo acontecer ou ser verdade, ou seja, dizer que é conclusivo é algo muito mais da análise após obtenção do dado minerado do que o próprio dado minerado em si, porém, o que salvou a questão foi o termo “subsidiar“, aí sim, a questão passa a se tornar verdadeira. Certa a questão.
Gabarito: CERTO.
CESPE 2015 TCU – Auditor Federal de Controle Externo – Tecnologia da Informação
No que concerne a data mining (mineração de dados) e big data, julgue o seguinte item.
Quem utiliza o data mining tem como objetivo descobrir, explorar ou minerar relacionamentos, padrões e vínculos significativos presentes em grandes massas documentais registradas em arquivos físicos (analógicos) e arquivos lógicos (digitais).
Comentários:
Vamos lá, o CESPE se superou na criatividade desta questão 🙂 , em nosso resumo, em momento algum vimos a possibilidade de realizar mineração de dados em arquivos físicos, ou seja, em pedaço de papel por exemplo. É lógico, que este papel poderia ser scaneado e se tornar um arquivo digital e a partir daí se aplicar um OCR e obter os dados desejados, porém nesta situação hipotética estaríamos diante de um arquivo digital e não um arquivo físico. Questão absurdamente errada.
Gabarito: ERRADO.
CESPE 2015 TCU – Auditor Federal de Controle Externo – Tecnologia da Informação
No que concerne a data mining (mineração de dados) e big data, julgue o seguinte item.
O uso prático de data mining envolve o emprego de processos, ferramentas, técnicas e métodos oriundos da matemática, da estatística e da computação, inclusive de inteligência artificial.
Comentários:
Questão “mamão com açúcar”. Vimos durante o resumo as tarefas previstas durante a mineração de dados e o que se espera produzir em cada uma delas. O que poderia causar dúvidas nesta questão é a utilização de “inteligência artificial”, que na verdade é a grande “cereja do bolo”, pois o uso de aprendizagem de máquina aliado com as diversas técnicas e métodos matemáticos, estatísticos e de computação, e por consequência o uso de inteligência artificial é capaz de gerar automação em interpretação de dados, ajudando diversas áreas de negócio. Certa a questão.
Gabarito: CERTO.
É isso aí pessoal, viram que às questões não tiveram nível de dificuldade tão alto nesta prova do TCU.
No próximo artigo, trarei mais questões do TCU/2015, forte abraço e bons estudos !
Luis Octávio Lima


Pingback: Big Data: Fases do Processo de Análise | Professor Rogerão Araújo