Olá pessoal!!
Vamos de mais um artigo sobre Big Data, agora falando das ferramentas e tecnologias utilizadas na etapas do processo de implantação e análise em Big Data. Para que este artigo não fique extenso e cansativo, será subdividido em 4 partes, cada parte correspondente a uma etapa do processo.

Recomendo fortemente a leitura dos artigos Big Data: Fundamentos e Conceitos e Big Data: Fases do Processo de Análise antes da iniciar a leitura deste artigo, pois muitos conceitos, terminologias e definições foram explicados em seu texto.
Este conjunto de artigos fecha o ciclo inicial do conhecimento básico sobre Big Data para concursos públicos. Este artigo, diferente dos demais, terá uma ênfase bem mais técnica devido ao fato de trabalharmos na perspectiva das tecnologias utilizadas e que são cobradas em questões de concursos.
Sem mais delongas, vamos ao que interessa! 😉
Como ponto de referência, vamos nos pautar pelas etapas do processo Big Data, conforme figura abaixo:

Coleta (capturando e armazenando dados)
Antes de pensar em qual será a forma de captura e armazenamento dos dados, se faz necessário ter respostas para as seguintes perguntas:
- Estes dados existem ou ainda serão gerados?
- São internos ou externos ao sistema ou à organização?
- Em quais formatos eles estão?
Parte destas respostas está em definir e quantificar os dos primeiros V’s do Big Data: Volume e Variedade dos dados (se está em dúvida sabre os V’s do Big Data, recomendo a leitura do artigo Big Data: Fundamentos e Conceitos). Com base nas respostas obtidas, novas questões surgem: será que o banco relacional será a melhor opção? Se não for, quais serão as melhores opções?
Capturando dados
Para captura do dados, se faz necessário realizar pesquisas da origem deste dados. Imaginem que parte destes dados estejam presentes na empresa/organização, como por exemplo:
- Dados de sistema de gerenciamento:
- Sistema de ERP;
- Dados do RH;
- Dados da intranet ou portal da organização;
- Arquivos:
- Documentos scaneados;
- Formulários;
- Correspondências;
- Noas fiscais;
- Documentos gerados pelos colaborados da organização:
- Planilhas em .xls, .xlsx;
- Relatórios em PDF;
- Dados em CSV, JSON;
- Documentos .docx, .doc;
- E-mails;
- Apresentações em .ppt
- Páginas em HTML/XML
- Sensores:
- Dados de câmera de segurança;
- Maquinários;
- Dados de sensores de carro;
- Registros de logs:
- logs de eventos;
- logs de servidores;
- logs de aplicações;
- logs da web.
É fácil deduzir o quão complexo e trabalhoso é fazer este primeiro levantamento, uma vez que muitas destas empresas ou entidades públicas nunca se preocuparam em organizar seus dados com a finalidade de gerar informação de confiança para tomada de decisão. É possível perceber que o V de Variedade é bem visível aqui.
Dentre a lista exemplificativa apresentada acima, chama atenção uma das fontes de dados: os sensores. Em questões de concursos, a utilização deste tipo de fonte de dados pode provocar dúvidas no candidato e uma forte tendência de considerar a questão como errada por falta de conhecimento. Para esclarecer está dúvida, vamos abaixo abordar o conceito de IoT (Internet of Things) ou “Internet das Coisas”:

O conceito de Internet das Coisas (Internet of Things – IoT) é o de uma enorme rede de dispositivos conectados. Computadores, celulares (smartfones), tablets, entre outros, são dispositivos que dependem da internet para funcionar apropriadamente. O foco da IoT é voltado para todos os demais equipamentos do dia a dia de um indivíduo, instituição, empresa ou mesmo de uma cidade inteira, aqueles que você não imaginaria em um primeiro momento que podem se beneficiar da rede.
Os equipamentos citados anteriormente são exemplos mais óbvios de dispositivos que migraram do mundo offline para o online, mas pense também em sua geladeira, fogão, lâmpadas, aspirador de pó, ar-condicionado, fechaduras, aparelho de som, carro, câmeras, sensores de vários tipos, dentre outros.
Todo este universo de equipamentos e “coisas” produzem dados, podendo ser aproveitados em uma grande base ou conjunto de outros dados, compondo o universo de dados do Big Data.
Suas principais características são:
- Grande fluxo de dados;
- Pouco conteúdo;
- Múltiplas fontes;
- Dados não estruturados.
Continuando ainda na captura dos dados, além de dados internos na empresa/organização, existem também dados que devem fazer parte do contexto do Big Data da organização, mas que não estão dentro da organização. São dados externos, em sua maioria vindos de:
- Dados de domínio público:
- Dados disponibilizados pelo governo, dados sobre o clima, tráfego e regulamentações, dados econômicos, dados do censo, de finanças públicas, legislação, comércio exterior e Wikipédia, dentre outros;
- Dados de sites de terceiros:
- Imagens, vídeos, áudios, podcasts, textos de comentários e revisões em sites da Web, dentre outros;
- Mídias sociais online:
- Twitter, LinkedIn, Facebook, Tumblr, SlideShare, YouTube, Google+, Instagram, Flickr, Pinterest, Vimeo, WordPress, RSS, Yammer, dentre outros.
Nesses tipos de dados, não somente o volume e a velocidade, mas também a variedade de dados disponíveis tornam sua captura, armazenamento e análise um desafio. Tendo em vista a existência deste desafio, as empresas e organizações detentoras destes dados disponibilizam as chamadas APIs (Application Programming Interface), que podemos definir como um conjunto de instruções, na maioria das vezes em forma de web services, para que os usuários tenham acesso aos dados de um aplicativo ou plataforma. Na administração pública existem alguma APIs disponíveis em http://www.dados.gov.br/.
Nesta fase de coleta de dados existem ferramentas que conseguem fazer esta captação e orquestração com a etapa de armazenamento. A mais conhecida delas é o Apache Kafka (https://kafka.apache.org/).
O Apache Kafka foi originalmente desenvolvido pelo LinkedIn e posteriormente liberado como um projeto open-source. O Apache Kafka é um sistema para gerenciamento de fluxos de dados em tempo real, gerados a partir de web sites, aplicações e sensores, possui a capacidade de lidar com fluxos de alta velocidade de dados, característica cada vez mais procurada para uso em Internet das Coisas.

Estes fluxos, conceitualmente, foram desenvolvidos como sendo um sistema de log distribuído. Isso significa que as mensagens enviadas ao Kafka são replicadas entre os nós do Cluster e salvas de modo sequencial, o que garante que ao lermos os registros eles serão entregues na mesma ordem na qual foram enviados. Estes logs conterão:
- Timestamp: data-hora da inserção;
- Offset: índice da mensagem na partição;
- Key: chave da mensagem;
- Value: a mensagem propriamente dita chamado de payload.
Armazenando Dados
Desta primeira etapa do processo (Coleta/Armazenamento de dados), o conhecimento sobre armazenamento é o mais cobrado nas provas. Isso porque grande parte dos dados coletados são não estruturados, o que requer a cobrança do conhecimento sobre tecnologias capazes de suportar dados neste formato. Não irei neste artigo abordar conhecimentos sobre SGBD pois este é assunto para outro artigo, irei focar nos modelos de armazenamento NoSQL, mas, por que? Vejamos !
- Escalabilidade:
- Quando falamos em grandes volumes e variedade de dados, precisamos de soluções que possam facilmente escalar os seus recursos de infraestrutura (armazenamento, memória, processamento), porém no caso de bancos SGBDs este escalonamento é vertical, moroso e custoso;
- O que se faz necessário é fazer uso do escalonamento horizontal;
- Para melhor entendimento sobre escalabilidade horizontal e vertical, recomento a leitura do artigo Big Data: Fases do Processo de Análise, onde abordo tais temas;
- Quando falamos em grandes volumes e variedade de dados, precisamos de soluções que possam facilmente escalar os seus recursos de infraestrutura (armazenamento, memória, processamento), porém no caso de bancos SGBDs este escalonamento é vertical, moroso e custoso;
- Alta disponibilidade:
- A garantia de integridade dos dados mantida pelos recursos disponíveis em um SGBD, pode ser um problema no tocante aos dados em grande volume e muito variáveis;
- No caso de dados não estruturados é possível abrir mão das regras do ACID (Atomicidade, Consistência, Isolamento e Durabilidade) e inclusive do uso da linguagem SQL, pois a violação das regras do ACID geram muitas vezes problemas de indisponibilidade;
- Parece controverso, mas é uma realidade, o excesso de regras ACID para o universo Big Data geram muitos problemas neste momento de coleta e armazenamento;
- Isso não quer dizer que haverá negligência com regras as de negócio da organização;
- Tal cuidado será tomado com maiores detalhes na fase de mineração dos dados e visualização;
- Parece controverso, mas é uma realidade, o excesso de regras ACID para o universo Big Data geram muitos problemas neste momento de coleta e armazenamento;
- No momento da captura e armazenamento, o foco é garantir a disponibilidade do funcionamento do fluxo de entrada dos dados;
- Neste aspecto, algumas literaturas apontam que em vez do ACID, é preferível o uso do BASE (Basically Available, Soft state, Eventual consistency), que traduzindo seria: Basicamente disponível, estado soft, consistência eventual.
- Flexibilidade:
- Em Big Data, não temos garantia do formato dos dados de entrada, ou seja, não existem modelos de dados pré-definidos (esquemas), ou seja, se faz necessário que a solução a ser usada seja flexível quanto a exigência prévia de esquema de dados.
Tendo em vista que diante do cenário de grande volume e variedade de dados, não temos como garantir um modelo de dados pré-definido, se faz necessário utilizar solução que não exija tais modelos e que possa trabalhar com dados não estruturados. O NoSQL (Not only SQL) surge então como solução para este cenário.
| Atenção: Não existe um modelo de armazenamento único que seja adequado para todos os cenários de aplicações, uma vez que cada solução requer necessidades específicas. Por exemplo, uma solução pode ter como requisito a gravação de informações em fluxos constantes ao banco, já outra pode necessitar de leituras periódicas em sua base. Para que cada uma dessas soluções tivessem recursos capazes de atender seus requisitos, diferentes modelos de armazenamento passaram a ser criados no contexto de NoSQL. |
É possível classificar os diferentes modelos em NoSQL de acordo com as diferentes estruturas de armazenamento de cada um, são eles:
Modelo orientado a chave-valor
- Estrutura mais simples dos bancos NoSQL;
- A chave geralmente é do tipo String, já o valor pode ser qualquer tipo;
- Usado tanto para persistir dados, quanto para ficar em memória formando caches;
- Adequado para aplicações de leituras frequentes;
- Pesquisa em banco fica limitada ao campo chave, não podendo fazer consultas mais elaboradas;
- Ideal para resolver questões de lentidão para leitura e escrita de dados em grande variedade e volume;
- Limitação: Campo valor não permite indexação.
- Pode armazenar documentos e imagens.

Exemplos de bancos de dados orientados a chave-valor:
- DynamoDB;
- Redis;
- Riak;
- Memcached.
Modelo orientado a documentos
- É uma extensão do modelo chave-valor;
- Pode criar índices sobre os dados armazenados;
- Pode realizar vários tipos de consultas e filtros nos valores armazenados e não somente no campo chave;
- Os documentos podem ser formados por dados semi-estruturados, como XML e JSON;
- Indicado para armazenamento de páginas Web e catalogação de documentos;
Exemplos de bancos de dados orientados a documentos:
- Couchbase;
- CouchDB;
- MarkLogic;
- MongoDB
Modelo orientado a colunas
- É uma extensão do modelo chave-valor, porém apresenta algumas características do modelo de banco relacional (criação de linhas e colunas);
- Busca resolver problemas de flexibilidade e escalabilidade no armazenamento de dados;
- No tocante a flexibilidade, ao invés de previamente definir as colunas serão responsáveis por armazenar registros, o responsável pela modelagem cria “famílias de colunas”, sendo estas famílias agrupadas de acordo com a frequência de dados utilizadas nas aplicações. O resultado é que cada registro vai receber as colunas que de fato foram utilizadas, sem precisar alterar a estrutura de dados (esquema) já armazenados;
- Tal flexibilidade não é possível em um SGBD relacional tradicional. 😉
- No tocante a flexibilidade, ao invés de previamente definir as colunas serão responsáveis por armazenar registros, o responsável pela modelagem cria “famílias de colunas”, sendo estas famílias agrupadas de acordo com a frequência de dados utilizadas nas aplicações. O resultado é que cada registro vai receber as colunas que de fato foram utilizadas, sem precisar alterar a estrutura de dados (esquema) já armazenados;
- Vejamos abaixo um exemplo:
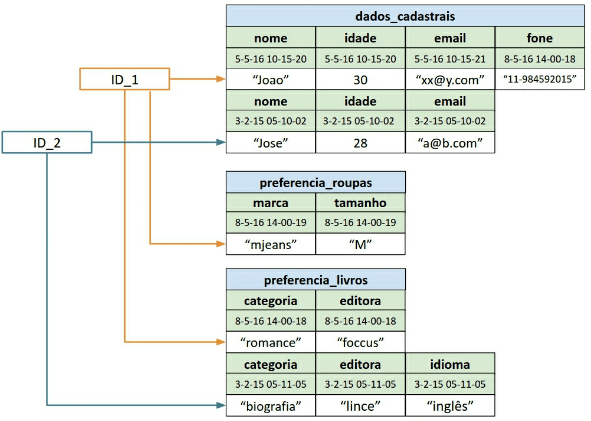
- É possível perceber na figura acima que o ID_1 (Joao) utiliza famílias de dados diferentes em relação a ao ID_2 (Jose) em preferencia_livros, por exemplo. E em dados_cadastrais, cada um dos IDs utilizam diferentes famílias. (tudo que a gente queria no modelo relacional e não podia 🙂 )
- Cada registro pode ter quantidade de colunas diferentes. Isso é possível pelo fato de que os dados são armazenados fisicamente em uma sequência orientada a colunas e não por linhas.
- Solução adequada para casos em que:
- Exista grande volume de dados;
- Necessite de alto desempenho e disponibilidade na leitura e escrita de dados;
- Inclusão de campos dinâmicos garantindo a disponibilidade;
- É utilizado por aplicações de larga escala, como por exemplo, o serviço de mensagens do Facebook.
Exemplos de bancos de dados orientados a colunas:
- Accumulo;
- Cassandra (o mais popular no mercado);
- HBase;
- Hypertable.
Modelo orientado a grafos
- Quando a estratégia requer saber mais do relacionamento dos dados, do que sobre o próprio dado;
- Em comparação com os demais modelos, o orientado a grafos é o mais especializado;
- Totalmente modelado utilizando a teoria dos grafos, utilizando vértices e arestas para armazenar dados dos itens que passaram pela coleta;
- Ao estabelecer o vínculo entre os dados, é possível definir este tipo de vínculo, criando rótulos de acordo com o negócio;
- Vejamos um exemplo:

Exemplos de bancos de dados orientados a grafos:
- AllegroGraph;
- ArangoDB;
- InfoGrid;
- Neo4J (o melhor, em minha opinião 😉 )
- Titan;
Bem, chegou a hora de praticar e conhecer como este assunto é cobrado pelas bancas de concursos. Vamos lá 😉
Questões de Concursos
[AOCP 2018 PRODEB – Especialista de TIC – Construção de Software] Com base nos sistemas de banco de dados NoSQL, assinale a alternativa que correlaciona corretamente os SGBD`s no NoSQL e seus modelos estruturais.
[A] MongoDB: Modelo Orientado a Colunas – Cassandra: Modelo Baseado em Grafos – Neo4J: Modelo Orientado a Documentos – Redis: Modelo Chave-Valor.
[B] Cassandra: Modelo Orientado a Colunas – Neo4J: Modelo Baseado em Grafos – Redis: Modelo Orientado a Documentos – MongoDB: Modelo Chave-Valor.
[C] Redis: Modelo Orientado a Colunas – Cassandra: Modelo Baseado em Grafos – MongoDB: Modelo Orientado a Documentos – Neo4J: Modelo Chave-Valor.
[D] Neo4J: Modelo Orientado a Colunas – Cassandra: Modelo Baseado em Grafos – MongoDB: Modelo Orientado a Documentos – Redis: Modelo Chave-Valor.
[E] Cassandra: Modelo Orientado a Colunas – Neo4J: Modelo Baseado em Grafos – MongoDB: Modelo Orientado a Documentos – Redis: Modelo Chave-Valor.
Comentários:
Essa questão é o tipo de questão “decoreba”, não tem jeito.
Durante o texto do artigo vimos os diversos modelos de armazenamento de banco NoSQL e exemplo de tecnologias existentes no mercado para cada modelo.
A letra E é a alternativa correta de acordo com o que estudamos durante o artigo.
Gabarito: letra E.
[CESPE 2019 SLU/DF – Analista de Gestão de Resíduos Sólidos – Informática] No que se refere a banco de dados relacional (SQL) e não relacional (NoSQL) e ao framework JPA, julgue o item subsecutivo.
Para uma empresa que necessite implantar uma base de dados altamente escalável, com grande desempenho e cujo esquema de dados seja flexível, de modo que suporte constantes mudanças de campos e valores armazenados, a melhor opção é uma base de dados NoSQL.
Comentários:
Durante o artigo batemos muito encima de algumas características: flexibilidade, desempenho, escalabilidade. No tocante a flexibilidade vimos que o modelo orientado a colunas é o ideal para o cenário apontado na questão. Questão certa e digna de ser usada para revisão em véspera de provas.
Gabarito: CERTO.
[CESGRANRIO 2018 Banco do Brasil – Escriturário] O termo NoSQL refere-se
[A] a uma abordagem teórica que segue o princípio de não utilização da linguagem SQL em bancos de dados heterogêneos.
[B] à renúncia às propriedades BASE (Basically Available, Soft state, Eventual consistency), potencializando seu espectrode uso.
[C] ao aumento da escalabilidade das bases de dados neles armazenados, aliado a um desempenho mais satisfatório no seu acesso.
[D] à facilidade de implementação de bases de dados normalizadas, com vistas a minimização de redundâncias no conjunto de dados.
Comentários:
Vamos por partes 🙂
Letra A: Errada. A banca tenta ludibriar o candidato mal preparado, tentando induzir ao trocadinho de NoSQL = Não utilização de SQL.
Letra B: Errada. É justamente o contrário, alguns autores pregam o uso das propriedades BASE ao invés do ACID, conforme vimos durante o artigo.
Letra C: Certa. Vimos durante o artigo que o uso do NoSQL diante de um grande volume e variedade de dados, oferece soluções satisfatórias no tocante a escalabilidade, performance, flexibilidade e disponibilidade.
Letra D: Errada. Totalmente errada. Vimos que as soluções NoSQL não priorizam a normalização em detrimento a prioridade em manter a disponibilidade.
Gabarito: letra C.
[CCV/UFC 2019 Técnico de Tecnologia da Informação – Desenvolvimento de Sistemas] Sobre os banco de dados NoSQL, assinale a afirmativa correta:
[A] Bancos de dados NoSQL não podem ser indexados.
[B] Bancos de dados NoSQL são considerados banco de dados relacionais.
[C] Nos bancos de dados NoSQL devem ser definidos um esquema de dados fixo antes de qualquer operação.
[D] São exemplos de bancos de dados NoSQL: MongoDB, Firebird, DynamoDB, SQLite, Microsoft Access e Azure Table Storage.
[E] Os bancos de dados NoSQL usam diversos modelos para acessar e gerenciar dados, como documento, gráfico, chave-valor, em memória e, pesquisa
Comtários:
Vamos analisar.
Letra A: Errada. Vimos que alguns modelos de banco de dados NoSQL apresentam a possibilidade de indexar campos.
Letra B: Errada. Não tem nem muito o que comentar. Os banso NoSQL são não normalizados.
Letra C: Errada. Vimos que nas soluções envolvendo bancos de dados NoSQL, principalmente pelo volume e variedade de dados que são coletados, não se define um esquema prévio dos dados.
Letra D: Errada. Firebird, SQlite, Microsoft Access não são banco de dados NoSQL.
Letra E: Correta.
Gabarito: letra E.
Bem, termino aqui o artigo, nos encontramos na próxima parte.
Forte abraço e bons estudos. 🙂
Luis Octavio Lima

Pingback: BIG DATA: FERRAMENTAS E TECNOLOGIAS – PARTE 2 | Professor Rogerão Araújo