Olá pessoal, estamos aqui novamente !
Este é o segundo artigo da série Big Data para concursos públicos. Recomendo fortemente a leitura do primeiro artigo desta série Big Data: Fundamentos e Conceitos para que possam acumular alguns conceitos e características que serão implicitamente abordados neste artigo.
Então vamos lá, como estímulo, vamos nos inspirar nas palavras de Immanuel Kant: “Quem não sabe o que busca, não identifica o que acha.”. Mais adiante vocês entenderão o quanto isso é verdadeiro nos dias de hoje.
Desejo uma boa leitura à todos ! 😉

Teoria
No primeiro artigo (Big Data: Fundamentos e Conceitos) desta série, falamos dos 5 Vs do Big Data: Volume, Variedade, Velocidade, Veracidade e Valor, descrevemos sobre às características de cada um deles e vimos o quanto este assunto é cobrado nas questões de concursos públicos.
Chegou o momento de subirmos para outro degrau a mais no conhecimento e perceber como as organizações, sejam públicas ou privadas, precisam se preparar para lidar com o Big Data com a finalidade obter ótimos insights a partir de uma grande variedade e volume de dados, vindo de diversas fontes.
Para isso, vamos conhecer as etapas previstas para o Big Data, desde a coleta até a interpretação do dado.
Coleta ou Aquisição dos Dados
Todo projeto de Big Data deve ser norteado por um objetivo específico, sendo necessário saber onde se quer chegar com os dados obtidos. Por mais que algumas empresas optem por fazer amplas coletas de dados e depois verificar de que forma eles podem ser utilizados (o que muitas vezes é um erro, deixar para verificar depois o que se pode fazer com estes dados, pois um grande investimento foi feito até então), há sempre um ponto central a ser trabalhado. O marketing, por exemplo, pode se beneficiar de informações relacionadas ao comportamento do consumidor.
Assim, na primeira etapa de Big Data, será feita uma coleta de dados para armazenamento. Mesmo que a empresa adote a ideia de armazenar diferentes dados para possíveis aplicações futuras, é essencial garantir que eles cubram ao menos os critérios relevantes para o objetivo principal.
Nesse momento devem ser analisados o volume e a variedade dos dados que serão coletados. É necessário que se faça uma limpeza, formatação e validação dos dados coletados, para que sejam eliminados erros, dados incompletos e incoerentes, evitando assim contaminar análises futuras.

Uma vez definido o que se deseja com os dados, se faz necessário obter respostas para algumas importantes indagações (leiam novamente o que disse Immanuel Kant, no início do artigo): Esses dados já existem ou ainda precisa ser gerados? São internos ou externos? Em qual formato eles estão?
São perguntas importantes que precisam ter respostas, pois irão impactar diretamente na etapa de coleta dos dados, pois a depender das respostas, surgem outras indagações importantes: Será que o banco de dados relacional é a melhor opção? Caso não seja, quais são as outras opções? Um banco de dados não relacional resolveria?
Limpeza dos Dados
Também chamada de “pré-processamento” dos dados, trata-se de etapa importantíssima nesta fase do processo. Nela, são identificadas anomalias ou discrepâncias que possam comprometer a análise como um todo. É uma etapa que exige um cuidado enorme, para não serem feitas transformações equivocadas nos dados.
A limpeza é feita por meio de um processo de inspeção dos dados coletados. Para isso, é possível aplicar alguns métodos estatísticos que avaliam desvios e, com base em alguns critérios, definem a sua relevância para a análise a ser feita.
Isso significa, na prática, que dados considerados anômalos (valores nulos, inconsistentes, duplicados etc.) serão removidos ou tratados para evitar que causem algum tipo de viés nos insights gerados. No entanto, vale destacar que a limpeza permite também o enriquecimento da base de dados, sugerindo novos parâmetros para a coleta.
O grande desafio desta etapa é lidar com o grande volume e variedade de dados coletados. Serão necessários ser desenvolvidos algoritmos capazes de lidar com tal volume, volume este que pode chegar na ordem de terabytes ou até petabytes de dados. A palavra chave deste grande desafio é: Escalabilidade.
Em projetos de Big Data, é crucial um planejamento que permita escalar a plataforma de acordo com a demanda. Também é necessário que essa plataforma ofereça alta disponibilidade, ou seja, que consiga se manter ativa mesmo diante de falhas que venham a ocorrer (e digo com certeza, elas ocorrerão).
Para que este desafio da escalabilidade encontre amparo, existem atualmente duas abordagens muito utilizadas no mercado, são elas: a Escalabilidade Vertical e a Escalabilidade Horizontal:
A Escalabilidade Vertical (Scalling-up) é o termo utilizado para alcançarmos maior performance da nossa aplicação utilizando o melhor e mais rápido hardware. Isso inclui a adição de mais recursos nos equipamentos, tais como: Memória, Processador e Discos.

A escalabilidade vertical também nos permite utilizar a tecnologia de softwares de virtualização, uma vez que esse software fornece mais recursos para os módulos hospedados no SO (Sistema Operacional), esse recurso também pode ser chamado de ampliação, como a expansão de processos. A escalabilidade do aplicativo refere-se ao melhor desempenho das aplicações em execução.
No entanto, não demorará muito para atingir o limite de hardware que pode ser usado no mesmo servidor, não sendo possível mais aumentar o tamanho da RAM ou a quantidade de CPUs infinitamente. Como consequência muitas aplicações precisaram se adaptar à escalabilidade horizontal para se manterem adequadas às necessidades de Big Data.
Além disso, centralizar o processamento em um único servidor não é uma boa ideia, pode ser perigoso, porque não é uma estratégia tolerante a falhas, visto que todo o sistema ficará indisponível se o servidor travar.
A Escalabilidade horizontal – (Scalling-out), diferente da vertical, significa adicionar mais recursos para um conjunto de servidores. Adiciona-se mais equipamentos servidores, sem que haja (na maioria das vezes) substituição dos que já existem.

É possível deduzir que a necessidade de mais espaço físico se torna necessário uma vez que mais equipamentos são adquiridos, porém isso nem sempre é verdade, pois muitos destes equipamentos são fisicamente menores se comparados com equipamentos mais antigos. Cada equipamento possui seus recursos de forma independente, porém trabalham de forma compartilhada uns com os outros, executando suas atividades de forma distribuída.
Ao conjunto de número definidos de equipamentos que se comportam de forma distribuída dar-se o nome de “cluster”, sendo este “cluster” incrementado com novos equipamentos quando a demanda por dado e processamento requeira mais recursos.
A escalabilidade horizontal apresenta uma série de vantagens para execução de aplicações Big Data, tais como:
- Permitir que o desempenho da aplicação seja aperfeiçoado de acordo com a demanda;
- Redução de custos para realização de upgrades da infraestrutura, quando comparado do a escalabilidade vertical;
- Oferece a possibilidade de escalabilidade ilimitada, isso principalmente em ambientes de computação em nuvem. (Sugiro a leitura do artigo Big Data e a Computação em nuvem)
Mas, nem tudo é máquina e equipamento para conseguirmos a melhor escalabilidade aplicada para Big Data, sendo necessária adaptações das aplicações para este cenário. A escalabilidade horizontal exige que o software gerencie a distribuição de dados e as complexidades existentes no processamento paralelo, podendo ter o seu desempenho comprometido, caso isso não seja realizado.
Com isso surgem novas tecnologias capazes de adaptar a escalabilidade horizontal de forma eficiente e com complexidade reduzida. Estas tecnologias em Big Data serão abordadas no próximo artigo desta série.
Análise dos Dados
Recomendo a leitura do artigo QUESTÕES COMENTADAS DO TCU 2015: DATA MINING para melhor conhecimento de alguns conceitos e técnicas sobre Mineração de Dados, pois falaremos de forma resumida sobre este assunto neste artigo, vamos em frente :).
“Estamos nos afogando em informações e famintos por conhecimento”
John Naisbitt – Escritor americano e autor do best seller Megatrends
Passamos pelas fases da Coleta (aquisição do dado) e Limpeza (pré-processamento do dado) e como já temos conhecimento dos 5 Vs, com destaque para o Volume e Variedade, estamos diante de uma “pancada” de dados.
A atividade de analisar dados não é nenhuma novidade, mas tem tomado força nos últimos anos devido ao potencial destes dados gerados em tão grande volume, não o dado pelo dado em si, mas a informação e o conhecimento que este dado gera, esta sim é a “cereja do bolo” tão almejada pelas organizações públicas e privadas.
As técnicas de mineração de dados tem forte participação nesta etapa do processo Big Data, ela é realizada computacionalmente e pode ser definida como um processamento de dados para a identificação de padrões. Para isso, podem ser utilizados métodos de Inteligência Artificial, Machine Learning, estatística, dentre outros.
Nesta fase de análise dos dados já preparados, é dado início à fase de modelagem dos dados. É daqui que surgirão os diversos algorítimos que darão auxílio na geração das respostas que se busca com o grande Volume e Variedade dos dados até o momento coletados. O objetivo é construir um modelo que com a implementação/utilização destes algorítimos específicos seja possível obter tais respostas, para isso, algumas tarefas comuns da Mineração de Dados serão realizadas , conforme figura abaixo:
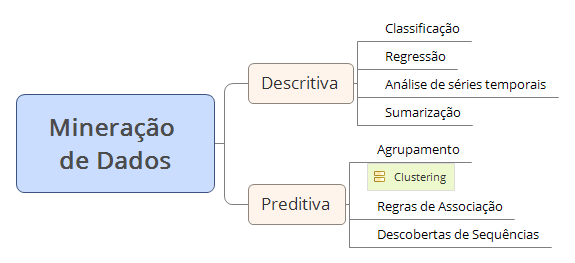
Sugiro a leitura do artigo QUESTÕES COMENTADAS DO TCU 2015: DATA MINING onde abordo cada uma destas tarefas.
Bom, mas..será que o modelo construído está correto? Será que vai fornecer ao final respostas válidas para o contexto aplicado? …Então, faço uma pergunta: Já ouviu falar que uma informação errada é pior do que nenhuma informação?
Pois é, é chegada a hora da Validação do Modelo, onde o desempenho do modelo será avaliado por meios de dados reais, sendo que estes dados não foram utilizados na etapa de treinamento do modelo. O treinamento do modelo é feito usando os algorítimos específicos, onde o objetivo final é a construção do aprendizado de máquina (Machine Learning). Este treinamento é feito com a massa de dados que já foi submetida à fase de limpeza e pré-processamento.
Machine Learning, ou aprendizado de máquinas, é a área da inteligência artificial relacionada à busca de um conjunto de regras e procedimentos para permitir que as máquinas possam agir e tomar decisões baseadas em dados, ao invés de serem explicitamente programadas para realizar uma determinada tarefa.
Dessa forma, ao analisarem um grande volume de informações, elas são capazes de identificar padrões e de tomar decisões com o auxílio de modelos. Isso torna as máquinas capazes de fazer predições por meio do processamento de dados.
O grande objetivo da validação do modelo é reduzir ou eliminar a chance de haver falsos positivos ou negativos nas respostas obtidas através do modelo, e consequentemente evitar que um gestor tome uma decisão errada com base nesta informação.
É nessa etapa do Big Data que são relacionadas questões possivelmente relevantes para cada situação, a depender do objetivo de quem aplica. Uma dúvida comum é por que a mineração seria capaz de relacionar padrões de comportamento que um olhar humano aguçado não veria?
A resposta, na verdade, sugere uma revisão da pergunta. A capacidade de o Big Data oferecer insights relevantes está justamente no fato de não olhar para padrões de comportamento humano, mas de dados em geral. Desta forma, o foco é na análise estatística e com base nela a descoberta de padrões, padrões estes que podem definir ou presumir o comportamento humano.
Se os dados mostram, por exemplo, que clientes que compram uma determinada marca de perfume também compram cerveja alemã na maioria das vezes, essa informação deve ser aproveitada. Não importa se a relação lógica está ou não explícita — o fato é que ter essa informação pode beneficiar o comerciante dos respectivos produtos e seus derivados.
A análise dos dados pode ter diferentes objetivos (as necessidades da organização é quem define ) e, para cada um deles, diferentes categorias de análises podem ser aplicadas, são elas: descritiva, diagnóstica, preditiva e prescritiva.
Para entender o cenário econômico no qual a empresa atua, por exemplo, a análise descritiva focada em dados passados (históricos) pode ajudar a entender a real situação da organização no presente, através do uso de indicadores e gráficos em dashboards ou relatórios estáticos, necessitando da participação humana na questão de interpretação destes indicadores e gráficos, bem como na tomada e decisão, ou seja, nesta categoria não são usados recursos de automatização para indicativos de possíveis ocorrências futuras, ficando a cargo deste ser por intervenção humana.
A análise diagnóstica ajuda a elucidar cadeias de acontecimentos relacionados à ocorrência (obtidas na análise descritiva), procurando entender o que pode te ocorrido para que um determinado cenário tenha passado a existir na organização. Diferente da análise descritiva, utiliza-se ferramentas de visualização mais interativas, afim de identificar padrões e tendências.
Já a análise preditiva visa a identificar padrões para prever possíveis cenários futuros e dar base para as decisões a serem tomadas. O olhar passa ser o futuro, tanto em termos de riscos, como de oportunidades para a organização. Nesta categoria são usados recursos mais avançados, como o aprendizado de máquina por exemplo (Machine Learning), sendo assim trata-se de uma categoria de análise mais complexa do que a descritiva e diagnóstica.
Por fim, a análise prescritiva mostra ao gestor possíveis resultados de uma ação tomada em um determinado cenário, auxiliando no ajuste da estratégia para que os objetivos sejam alcançados. Trata-se de um novo nível de inteligência utilizado nas aplicações, graças a evolução das diversas soluções de Big Data. A análise prescritiva completa a etapa da análise preditiva, fornecendo a capacidade inteligente de sugerir ou propor ações estratégias para resolver problemas detectados.
Segue abaixo uma figura Bizu do Luis para ajudar a memorizar estas quatro diferentes categorias de análise:

Visualização e Interpretação dos Dados
Bem, até o momento já coletamos, limpamos, analisamos e construímos/validamos um modelo. Estamos chegando na etapa final do projeto Big Data.
É possível compreender o processo todo como uma melhoria na forma de visualizar os mesmos dados. De uma forma ou de outra, todas as informações extraídas do Big Data estão, na verdade, disponíveis naquele vasto banco de dados. Entretanto, é preciso transformá-la em algo de fácil interpretação para as pessoas que terão acesso aos resultados, contribuindo para o aumento da percepção através da visualização dos dados de forma simplificada.
Assim, a visualização de informações é uma etapa de remodelagem dos resultados extraídos. Nela, são feitas adaptações gráficas que favorecem uma interpretação otimizada, eliminando ruídos e fatores que desviem o foco durante a análise.
Gráficos, por exemplo, são ferramentas visuais de extrema importância para facilitar o entendimento. No entanto, a etapa de visualização não se resume apenas a transformar tabelas em gráfico — primeiro, é preciso estabelecer os seus objetivos.
Conhecer as pessoas que terão acesso aos dados é fundamental. Além disso, é preciso avaliar o que exatamente elas buscarão naquele documento. Uma mesma análise de Big Data pode resultar em diferentes visualizações, cada uma visando a facilitar a interpretação de um determinado “público-alvo”, ou seja, gestores de diferentes departamentos.
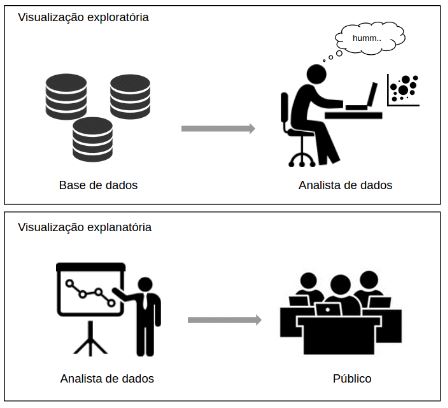
Neste momento é importante identificar se o propósito da visualização é para fins de exploração ou explanação/explicação dos dados. Vejamos algumas características destes possíveis propósitos:
Visualização Exploratória:
Trata-se do aprofundamento do conhecimento sobre o dado de forma minuciosa, feita geralmente por um Analista de Dados, para então decidir que operação será feita com estes dados. Neste tipo de visualização o formato final apresentado não é tão amigável para um usuário final, como um gestor, quanto a visualização explanatória.
Visualização Explanatória:
Estando os dados revisados e corretos (etapa exploratória) os resultados então podem ser mostrados para o público, ocorrendo a explanação dos dados. Neste momento, o objetivo não é mais fazer a descoberta dos dados, mas sim enfatizar de forma eficaz o que já foi descoberto, buscando facilitar a compreensão das informações que não participaram o processo de análise dos dados.
Então, resumindo o processo de análise em Big Data:

Bem pessoal, esta é a parte teórica, quanto às questões de concursos sobre este assunto, especificamente são poucas, mas a minha intenção foi dar embasamento para o próximo artigo onde abordarei as tecnologias utilizadas em cada uma das etapas deste processo, isto sim, é mais cobrado nas provas de concursos.
De qualquer forma e para não perdermos o costume, separei algumas questões para comentarmos, simbora !! 🙂
Questões de concursos
[FCC 2018 SABESP – Analista de Gestão] Considere a notícia abaixo.
Uso do big data auxilia negócios e esforço de recuperação fiscal
O uso do big data na tomada de decisões está aos poucos se consolidando no mundo dos negócios, com empresas reportando resultados concretos. […] A empresa iniciou projeto de big data em março do ano passado: o objetivo, de acordo com o especialista de inteligência competitiva, Nilton Brum, foi saber se a base de clientes ‘está comprando tudo o que nós podemos vender‘.
(Adaptado de: https://www.dci.com.br)
De acordo com o texto apresentado, inteligência competitiva é a
[A] alimentação do servidor da empresa com informações sobre os principais clientes e suas potencialidades.
[B] criação de software que reúna as informações que serão analisadas por uma equipe multiplataforma e multidisciplinar.
[C] antecipação das exigências do mercado por meio de gestão estratégica que reúna informações sobre clientes, concorrentes e fornecedores.
[D] capacidade de eliminar os concorrentes se antecipando aos pregões, licitações e concorrências assim que são publicados.
[E] reunião dos principais talentos do mercado por meio de criterioso processo de seleção e recrutamento.
Comentários:
Letra A: alimentação do servidor da empresa com informações sobre os principais clientes e suas potencialidades.
ERRADO. O texto trata de uma base já existente, sendo analisado os dados que refletem o comportamento dos mesmo perante o consumo dos produtos ofertados pela organização.
Letra B: criação de software que reúna as informações que serão analisadas por uma equipe multiplataforma e multidisciplinar.
ERRADO. A criação de software da forma como está descrito foge ao contexto do texto apresentado no tocante a inteligência competitiva.
Letra C: antecipação das exigências do mercado por meio de gestão estratégica que reúna informações sobre clientes, concorrentes e fornecedores.
CERTO. Trata-se da análise preditiva das informações, tendo como foco a construção de inteligência competitiva com base em informações que envolvam clientes, empresas concorrentes do mercado e fornecedores de produtos.
Letra D: capacidade de eliminar os concorrentes se antecipando aos pregões, licitações e concorrências assim que são publicados.
ERRADO. Esta seria uma possível ação a ser tomada como consequência da inteligência competitiva, mas não é a inteligência competitiva em si, esta é mais abrangente.
Letra E: reunião dos principais talentos do mercado por meio de criterioso processo de seleção e recrutamento.
ERRADO. Esta seria uma possível ação a ser tomada como consequência da inteligência competitiva, mas não é a inteligência competitiva em si, esta é mais abrangente.
Gabarito: letra C.
[CESPE 2018 TCE/MG – Analista de Controle Externo – Ciência da Computação] Uma empresa, ao implementar técnicas e softwares de big data, deu enfoque diferenciado à análise que tem como objetivo mostrar as consequências de determinado evento.
Essa análise é do tipo:
[A] preemptiva.
[B] perceptiva.
[C] prescritiva.
[D] preditiva.
[E] evolutiva.
Comentários:
A parte da questão que define a resposta está em: “…tem como objetivo mostrar as consequências de determinado evento..”
No artigo vimos as seguintes categorias de análise dos dados:
“Para entender o cenário econômico no qual a empresa atua, por exemplo, a análise descritiva focada em dados passados (históricos) pode ajudar a entender a real situação da organização no presente, através do uso de indicadores e gráficos em dashboards ou relatórios estáticos, necessitando da participação humana na questão de interpretação destes indicadores e gráficos, bem como na tomada e decisão, ou seja, nesta categoria não são usados recursos de automatização para indicativos de possíveis ocorrências futuras, ficando a cargo deste ser por intervenção humana.
A análise diagnóstica ajuda a elucidar cadeias de acontecimentos relacionados à ocorrência (obtidas na análise descritiva), procurando entender o que pode te ocorrido para que um determinado cenário tenha passado a existir na organização. Diferente da análise descritiva, utiliza-se ferramentas de visualização mais interativas, afim de identificar padrões e tendências.
Já a análise preditiva visa a identificar padrões para prever possíveis cenários futuros e dar base para as decisões a serem tomadas. O olhar passa ser o futuro, tanto em termos de riscos, como de oportunidades para a organização. Nesta categoria são usados recursos mais avançados, como o aprendizado de máquina por exemplo (Machine Learning), sendo assim trata-se de uma categoria de análise mais complexa do que a descritiva e diagnóstica.
Por fim, a análise prescritiva mostra ao gestor possíveis resultados de uma ação tomada em um determinado cenário, auxiliando no ajuste da estratégia para que os objetivos sejam alcançados. Trata-se de um novo nível de inteligência utilizado nas aplicações, graças a evolução das diversas soluções de Big Data. A análise prescritiva completa a etapa da análise preditiva, fornecendo a capacidade inteligente de sugerir ou propor ações estratégias para resolver problemas detectados.”
A questão apresenta uma forma de aplicação da análise prescritiva, então a resposta é a alternativa c.
Gabarito: letra C.
Bom, vou ficando por aqui !
Fiquem atentos ao próximo artigo, nele falarei sobre as diversas tecnologias aplicadas no processo Big Data em cada uma das etapas que estudamos neste artigo.
Forte abraço, bons estudos e até o próximo artigo.
Luis Octavio Lima

Pingback: Big Data: Ferramentas e tecnologias – Parte 1 | Professor Rogerão Araújo
Pingback: Big Data: conceito e o ciclo para geração de valor - Safegold
Pingback: BIG DATA: FERRAMENTAS E TECNOLOGIAS – PARTE 2 | Professor Rogerão Araújo